
Ein jeder dürfte in Zeiten der omnipräsenten Suchmaschinenoptimierung mit meta-tags à la Title, Description etc. vertraut sein. Auch die „robots“-Direktive ist den Meisten ein Begriff – kann man so doch sehr granular die Sichtbarkeit bei Google & Co. aussteuern.
Aktuell trat ein Kunde an mich heran, der seine (statische) Seite aus dem Index entfernt haben wollte. Eine manuelle Editierung stand ausser Frage (ca. 100 individuelle Dateien), einen Header-Insert o.ä. gab es auch nicht. Gut, dass es den X-Robots-Tag gibt…
Vorteile der Verwendung von „X-Robots-Tag“ zur Aussterung der Meta-Informationen
Die Befehle für den X-Robots-Tag können in die .htaccess (bzw. die httpd.conf) Eures Apache-Servers geschrieben werden und steuern die Seite ab sofort global mittels des HTTP-Headers – keine kleinteiligen Anpassungen nötig!

Wichtig zu erwähnen ist dabei, dass der X-Robots-Header gewissermaßen „über“ den regulären Seiteninformationen sitzt und dadurch Vorrang vor den regulären meta-Angaben genießt. Im Klartext kann eine Seite also eine Direktive wie
<meta name="robots" content="index">enthalten, diese wird aber durch den X-Robots-Tag überschrieben.
Der X-Robots-Tag in der Anwendung
Wir bedienen uns einfach an der bekannten Apache-Syntax:
<Files ~ "\.doc$">
Header set X-Robots-Tag "noindex, nofollow"
</Files>Im Beispiel werden sämtliche Word-Dokumente mit einem noindex, nofollow versehen. Wer direkt seine ganze Seite ansprechen will verzichtet auf „Files“ bzw. „FilesMatch“ und setzt den Header ohne Einschränkungen:
Header set X-Robots-Tag "noindex, nofollow"Was aber tun, wenn ich zwar die Vorzüge der globalen Einstellung für mich nutzen möchte, dennoch aber bestimmte Dokumente von der Zuteilung eines X-Robots-Tags ausnehmen möchte? Das war eigentlich auch die Motivation für diesen Snippet-Post, denn hierzu gab es erstaunlich wenig Informationen / How-To’s im Netz…
Mein Case / meine Lösung greift dabei auf „FilesMatch“ zurück und nutzt eine Art ‚Negativ‘ / eine ‚Inversion‘, die ein globales Setting unter Ausschluss von einzelnen Dateien herstellt:
<FilesMatch "^(?!MEINE-ERSTE-DATEI\.php$|MEINE-ZWEITE-DATEI\.html$).+">
Header set X-Robots-Tag "noindex, noarchive, nosnippet"
</FilesMatch>Auf diese Art und Weise bekommen alle Seiten und Dateien mit Ausnahme von MEINE-ERSTE-DATEI.php und MEINE-ZWEITE-DATEI.html den Robots-Tag versehen.
Den Index-Auschluss kontrollieren
Da der X-Robots-Tag im HTTP-Header sitzt, muss man logischerweise auch dort nachschauen wenn man die Funktionalität überprüfen möchte. Geht m.E. am Besten mit dem Firefox-AddOn Live HTTP Headers. So sieht das Ganze aus:
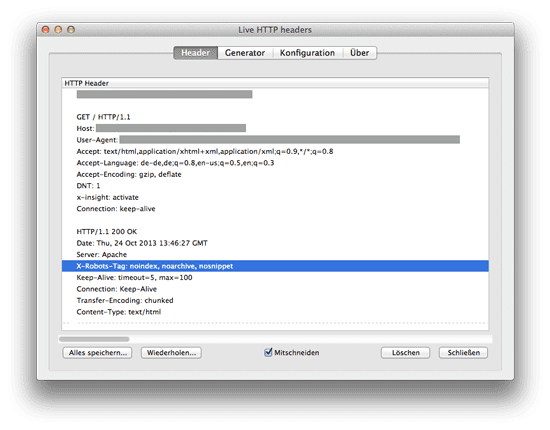
Hoffentlich hilft die Anleitung dem ein oder anderen, der sich mit Meta-Tags beschäftigt und eine gute Lösung für die globale Verwaltung auf Server-Ebene sucht.
Danke – das hab´ ich gesucht!